

Console.Write("Hello World!");







Você já ouvir falar sobre a técnica Bubble Sort?
Bubble Sort (ou ordenação em bolha) é um algoritmo de ordenação numérica que consiste em reorganizar os valores de uma coleção (normalmente arrays) de forma que os mesmos sejam reposicionados em ordem decrescente de acordo com o índice da coleção.
Em linguagens de programação como o C# por exemplo, temos funções de ordenação através de LINQ, assim como é feito com dados de tabelas em SQL (vide função OrderBy), mas não deixa de ser interessante estudar este algoritmo de ordenação para fins didáticos e treinar a lógica, mesmo porque, conhecer novos algoritmos e técnicas, nunca é demais.
Como funciona?
O algoritmo consiste em apenas ''trocar'' os valores de um array, de forma que os maiores valores ocupem os primeiros índices, fazendo com que os menores, obviamente, vão ficando por último na indexação.
Graficamente falando, podemos ter como exemplo a seguinte situação (um array de inteiros):

Veja que ao final do processo o array está devidamente ordenado de forma decrescente, assim o maior valor ocupa o primeiro índice, e o menor valor ocupa o último índice da coleção.
Em programação:
Para realizar essa "troca" de valores dentro do array, primeiramente precisamos criar um laço de repetição que percorra toda a coleção, e a validação a ser feita dentro deste laço deve ocorrer sempre entre o elemento atual do laço e o elemento do índice sucessor, como foi feito no exemplo gráfico, onde trocamos os elementos sucessores se estes forem maiores que o elemento anterior.
Para realizar essa validação, deve ser criado outro laço de repetição que tenha um limite menor que o tamanho do array atual, assim evitamos que seja extrapolado o último elemento, ao verificar seu sucessor, que na verdade não há.
Quando se é verificado que o sucessor no array é maior que seu antecessor, realize-se a 'troca', ou seja, o maior valor passa a ocupar o índice de seu antecessor e o menor valor vai para o índice de seu sucessor. Para tal, basta criar uma variável temporária que armazene o valor do elemento do índice atual (para que ele não se perca), e o índice atual recebe o valor de seu sucessor, e o sucessor receba o valor da variável temporária.
Exemplo em C++
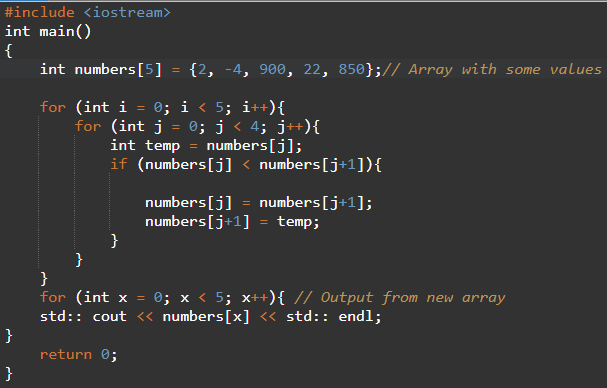
Exemplo em C#

Veja que através do output do array podemos visualizar como a coleção ficou ordenada de forma decrescente:

Claro que se você quiser ordenar o array em ordem crescente, basta trocar o sinal da validação do menor (<) para maior (>):
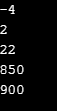
(saída em output do array em ordem crescente)
Os exemplos neste artigo foram feitos nas linguagens em C++ e C#, mas qualquer linguagem de programação que suporte arrays pode realizar a técnica do Bubble Sort.




")
")


 almas:
almas: